알고리즘 추천 시스템을 위한 '협업 필터링'이란?

요즘 세간에 이런 말이 있습니다, “그 사람의 취향을 알고 싶다면 유튜브 영상 기록을 봐라". 이 말인즉슨 사용자 데이터를 기반으로 취향을 분석할 수 있다는 것인데요, 이렇게 사용자 취향을 분석하는 것은 기업들에게 아주 중요한 마케팅 요소입니다.
온라인 비즈니스에서 고객의 사용 시간을 늘리기 위해 슈퍼 앱, AI 챗봇 등을 활용하며, 지속적인 고객 유입을 유도하기 위해 데이터 분석을 기반으로 알고리즘 추천 서비스를 실행하고 있습니다.
사용자 데이터 분석을 통한 개인화 추천 기술은 유튜브, 아마존, 쿠팡 등 다양한 비즈니스에서 이미 활발하게 활용되고 있는데요.
그럼 이런 알고리즘 추천 기능은 어떻게 구현하고 적용되는 걸까요? 대표적인 알고리즘 추천을 작동시키는 ‘협업 필터링’이란 무엇인지 그리고 어떻게 적용하는지 IT 인재 매칭 플랫폼 이랜서에서 알려드리겠습니다.
알고리즘 추천을 위한
협업 필터링(Collaborative Filtering)이란?
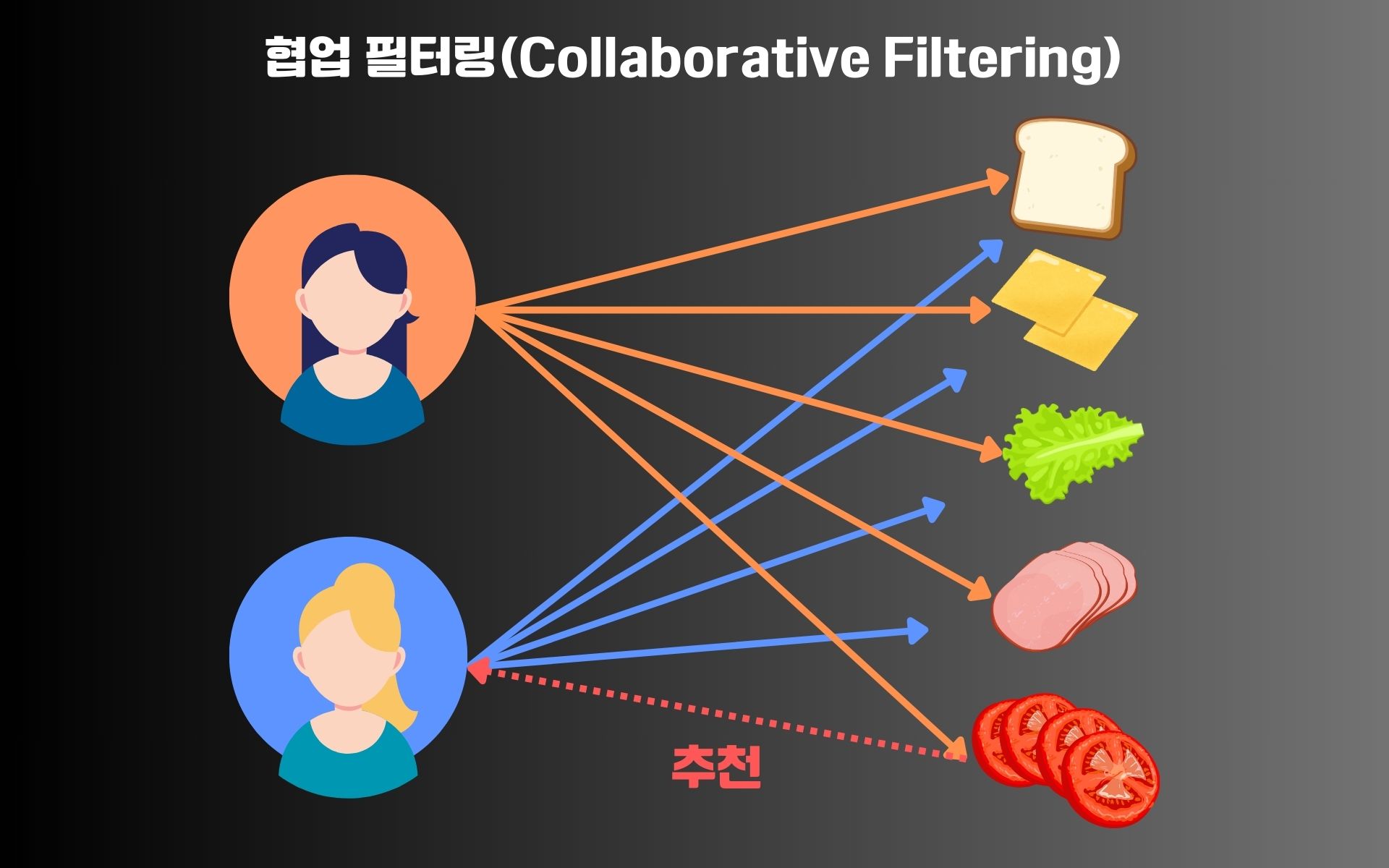
SNS 릴스나 유튜브 쇼츠 영상을 보다 보면 내가 요즘 관심 있는 제품에 대한 광고가 나온다거나, 이전에 봤던 내용과 비슷한 주제의 영상이 연속해서 추천된다는 것을 확인할 수 있습니다.
방금 찾아본 상품들, 방금 시청한 영상들과 비슷한 상품과 영상이 추천되는 것인데요, 이렇게 개인 맞춤형으로 제품이나 영상을 추천할 수 있게 하는 기술이 바로 '협업 필터링'입니다.
협업 필터링(Collaborative Filtering)은 추천 시스템의 핵심 알고리즘 중 하나로, 사용자와 항목 간의 유사성을 바탕으로 추천하는 방식입니다.
협업 필터링은 크게 ‘사용자 기반 협업 필터링(User-Based Collaborative Filtering)’과 ‘아이템 기반 협업 필터링(Item-Based Collaborative Filtering)’ 이렇게 두 가지 유형으로 분류되는데요, 이들의 개념과 적용 사례 그리고 알고리즘 구현 방법까지 알려 드리겠습니다.
알고리즘 추천을 작동시키는 협업 필터링의 유형
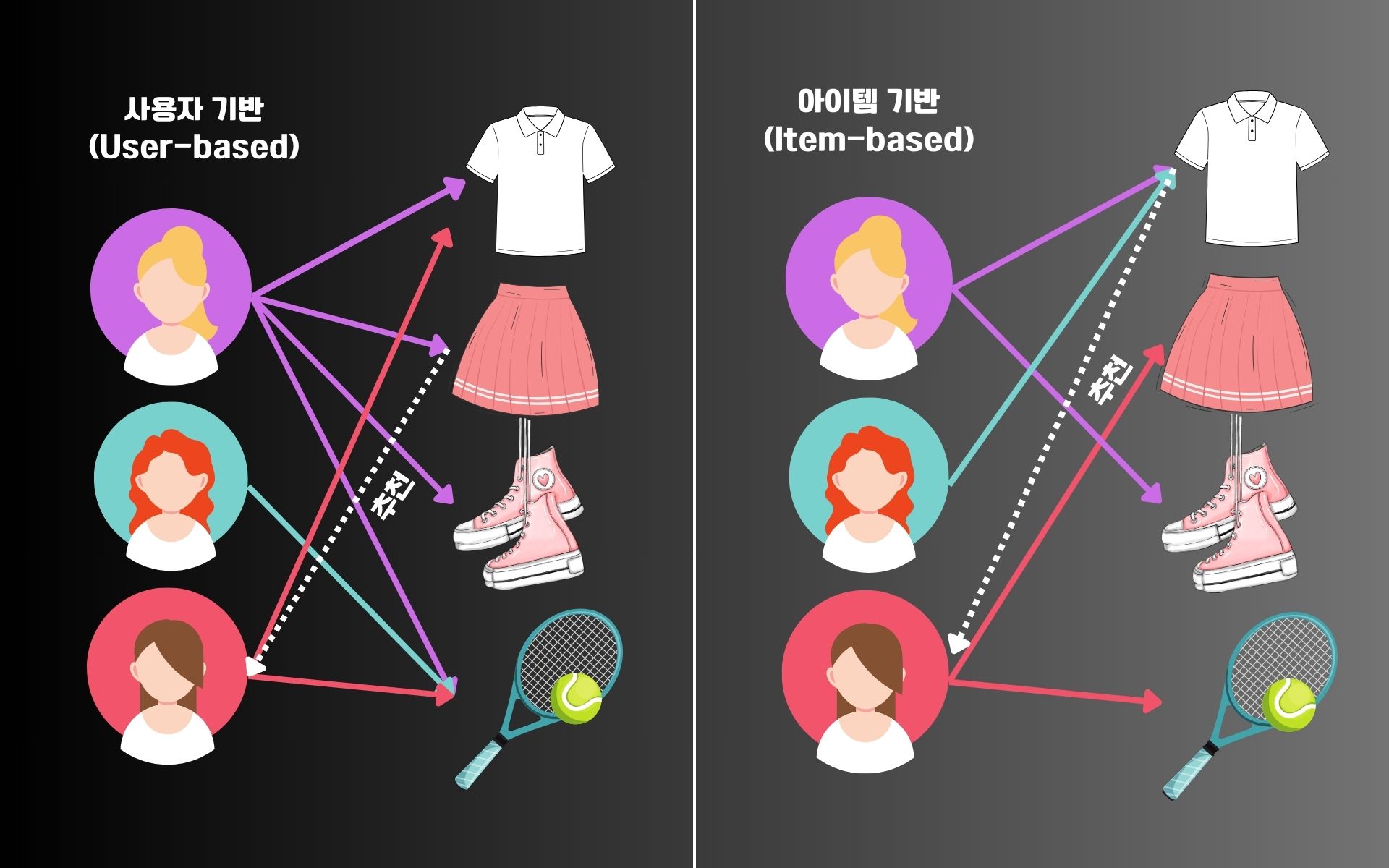
사용자 기반 협업 필터링(User-based)
사용자 기반 협업 필터링은 특정 사용자의 데이터와 유사한 다른 사용자를 찾아, 이들이 선호하는 항목을 추천하는 방법입니다.
사용자 기반 협업 필터링은 사용자 간의 유사도를 평가하고 유사한 취향을 가진 사용자 그룹의 데이터를 기반으로 제품 또는 콘텐츠를 추천합니다.
기존 사용자가 마라탕, 탕후루, 훠궈 구매 이력이 있고 신규 사용자가 마라탕, 탕후루를 장바구니에 담았다면 신규 사용자는 훠궈까지 고를 가능성이 높다고 판단하는 방식입니다.
아이템 기반 협업 필터링(Item-based)
아이템 기반 협업 필터링은 특정 아이템과 유사한 다른 아이템을 찾아, 사용자가 선호할 가능성이 높은 항목을 추천하는 방법입니다. 이는 아이템 간의 유사도를 계산하여 유사한 아이템을 추천하는 방식입니다.
예를 들어 카페 음료 간의 유사도를 계산한 상태에서 바닐라 라떼와 돌체 라떼의 유사도가 높다고 평가되면 바닐라 라떼 구매 이력이 있는 고객에게 돌체 라떼를 추천하는 방식이 되겠습니다.
협업 필터링 알고리즘의 적용사례
앞에서 설명드린 협업 필터링 유형들은 온라인 비즈니스나 서비스에서 어떻게 활용되고 있을까요? 협업 필터링이 활용되고 있는 서비스에 대해 소개 드리고 이러한 서비스에서는 협업 필터링을 어떻게 활용하고 있는지 알려드리겠습니다.
넷플릭스의 추천 알고리즘, 모델 기반 협업 필터링
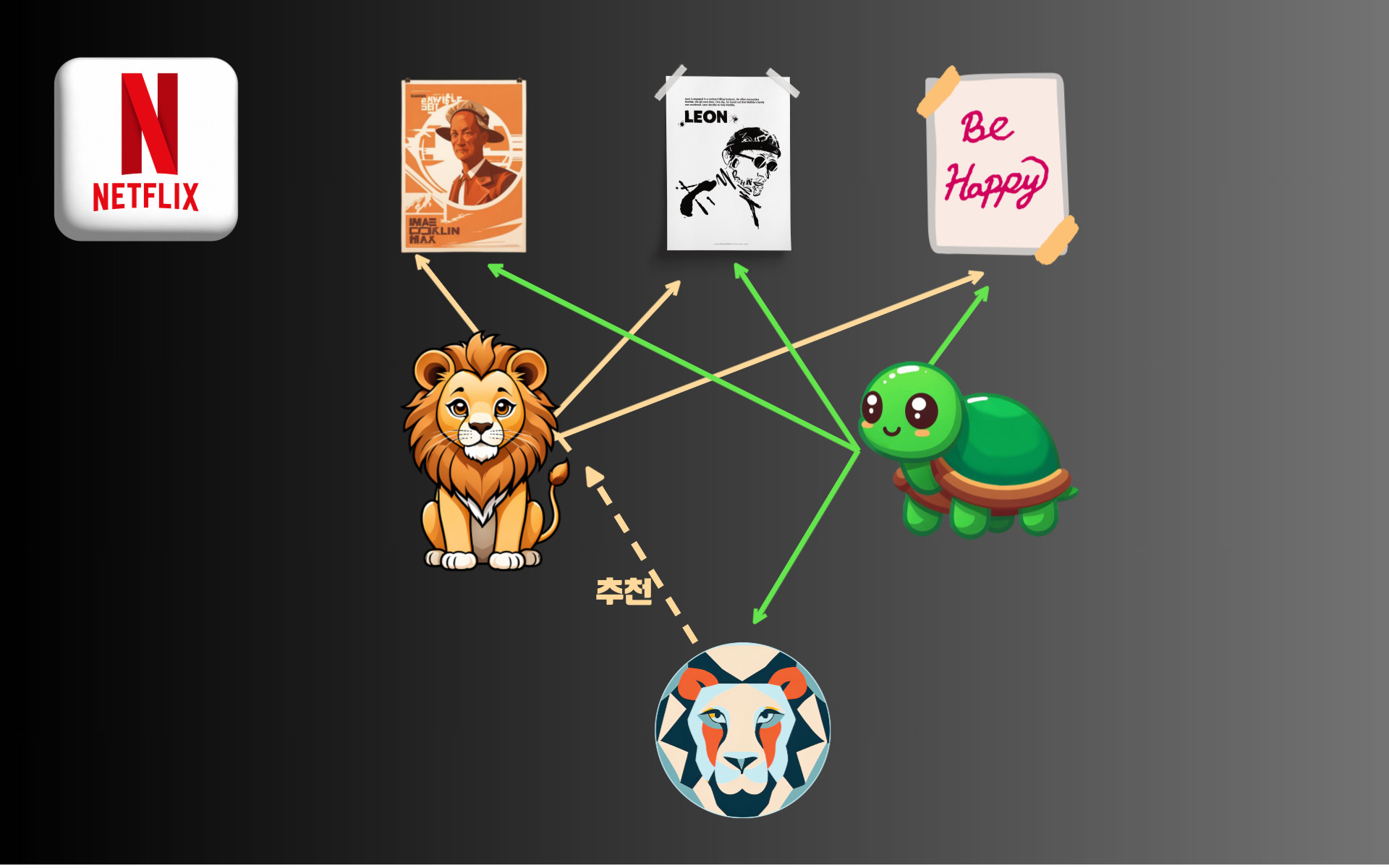
넷플릭스가 세계 최대의 OTT 플랫폼이 되기까지 막대한 자본력을 기반으로 한 다양한 콘텐츠가 큰 역할을 했지만 이에 못지않게 중요한 부분으로 작용한 것이 바로 ‘ 알고리즘 추천 시스템’입니다.
넷플릭스를 이용하시는 분들은 따로 검색하지 않아도 취향에 맞춘 영화들을 추천받으실 수 있는데요, 사용자 입맛에 맞는 콘텐츠를 큐레이션 해주는 기능이 서비스 만족도를 높이는데 큰 역할을 하고 있습니다.
현재 넷플릭스에서 사용하는 추천 알고리즘은 협업 필터링을 기반으로 한 모델 기반 협업 필터링으로 알려져 있는데요, 앞서 설명드린 협업 필터링을 고도화하여 콘텐츠 안에 내재되어 있는 패턴까지 추천에 활용하는 방식입니다.
이를 구현하기 위해 사용자의 시청 기록, 검색 이력, 평가 등의 정보를 수집하고 이를 활용하여 사용자와 콘텐츠 간의 상호 관계를 수치화한 협업 필터링 방식을 사용하고 있습니다.
아마존의 고객 분석과 아이템 추천을 담당하는 협업 필터링
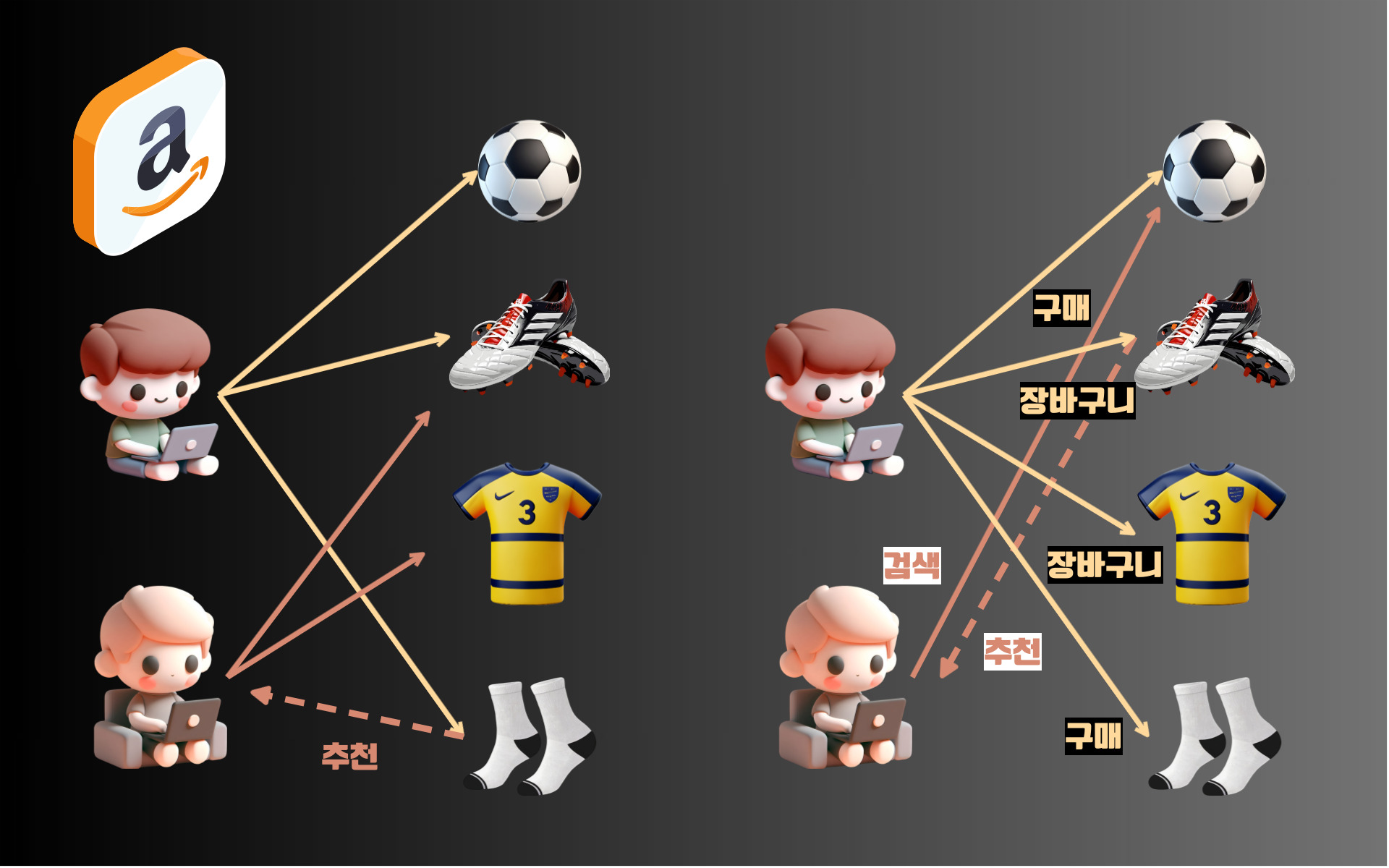
아마존은 협업 필터링을 활용하여 사용자에게 맞춤형 제품을 추천하고 있는데요, 아마존의 협업 필터링은 다음과 같은 방식으로 적용되고 있습니다.
1. 고객 구매 패턴에 의한 사용자 협업 필터링
아마존은 고객의 구매 이력과 행동 데이터를 분석하여 유사한 구매 패턴을 가진 사용자들을 그룹화하여 제품을 추천하고 있습니다.
사용자 기반 협업 필터링을 활용하여 특정 제품을 구매한 사용자가 이후 구매한 다른 제품들을 분석하여 비슷한 취향을 가진 사용자들에게 해당 제품을 추천하는 알고리즘입니다.
2. 장바구니에 담긴 제품 기반의 아이템 협업 필터링
아마존은 아이템 기반 협업 필터링도 적극 활용하고 있습니다. 사용자가 보고 장바구니에 담았거나, 구매를 한 제품과 유사한 제품을 추천하는 방식으로, 이를 통해 사용자가 보다 많은 아이템을 구매를 하도록 유도하고 있습니다.
협업 필터링 알고리즘은 각종 서비스에서 조회, 검색, 구매 등의 정보들을 바탕으로 다양한 제품, 콘텐츠를 추천하고 있으며 기업에서는 사용자의 취향을 잘 이해하고 최적의 추천 알고리즘을 구현하기 위해서 협업 필터링을 적극 활용하고 있습니다.
다음은 이런 협업 필터링 알고리즘을 어떻게 구현 가능한지 살펴보겠습니다.
알고리즘 추천 시스템 구현 방법
협업 필터링에 기반한 알고리즘 추천 시스템을 구현하기 위해서는 사용자의 데이터를 바탕으로 유사도를 평가하고, 이를 바탕으로 제품을 추천하는 함수 구현이 필요합니다. 각 기능을 어떻게 코드로 구현이 가능한지 알려드리겠습니다.
사용자 기반 협업 필터링의 구현
사용자 기반 협업 필터링은 유사한 사용자를 구하고, 해당 사용자들이 관심 있는 항목에 대해 추천하는 알고리즘입니다. 아래 예시 코드는 각 사용자의 영화 평점을 데이터로 정의하고 유사도를 계산하여 아이템을 추천하는 구현 예시입니다.
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
# 사용자, item(영화), rating(점수) 데이터
data = {
'user_id': [0, 0, 1, 1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4],
'item_id': [0, 1, 0, 1, 2, 4, 1, 3, 2, 3, 4, 2, 4, 2],
'rating': [5, 3, 5, 3, 5, 5, 5, 4, 5, 2, 4, 5, 4, 4]
}
# 사용자, 영화 인덱스 별 이름
user_list = [ "홍길동", "임꺽정", "이몽룡", "변사또", "이순신" ]
movie_list = [ "해리포터", "반지의제왕", "어벤저스", "엑스맨" , "배트맨" ]
# 데이터 프레임 생성
df = pd.DataFrame(data)
# 사용자-아이템 행렬 생성
user_item_matrix = df.pivot_table(index='user_id', columns='item_id', values='rating').fillna(0)
# 모든 사용자 간 유사도 계산
user_similarity = cosine_similarity(user_item_matrix)
# 데이터프레임으로 변환
user_similarity_df = pd.DataFrame(user_similarity, index=user_item_matrix.index, columns=user_item_matrix.index)
# 협업 필터링을 통한 추천알고리즘 함수
def runCF ( user_id ):
# 특정 사용자의 평점 예측, user 의 movie 예상평점
# 유사도 가중치를 고려한 평점 예측
similar_users = user_similarity_df[user_id].drop(user_id)
similar_users = similar_users[similar_users > 0]
user_ratings = user_item_matrix.loc[user_id]
weighted_sum = np.zeros(user_item_matrix.shape[1])
similarity_sum = np.zeros(user_item_matrix.shape[1])
for other_user in similar_users.index:
# 다른 사용자의 평점에 유사도를 곱하여 가중합 계산
weighted_sum += user_similarity_df.loc[user_id, other_user] * user_item_matrix.loc[other_user]
similarity_sum += user_similarity_df.loc[user_id, other_user]
# 0으로 나누는 것을 피하기 위해 0을 1로 대체
similarity_sum[similarity_sum == 0] = 1
predicted_ratings = weighted_sum / similarity_sum
# 상위 3 개의 추천 아이템 반환
recommendations = predicted_ratings.sort_values(ascending=False).head(3)
return recommendations
for u_idx, user in enumerate(user_list):
print("")
recoms = runCF( u_idx )
print(f'[ {user} 고객님을 위한 영화추천 3선 ]' )
for idx, item, in enumerate( recoms.to_dict().items(), start=1 ):
print(f"{idx}. {movie_list[item[0]]} \t( 예상평점: {item[1]:.1f} )") |
코드를 실행하면 runCF 함수는 협업 필터링 알고리즘을 통해 고객 간의 유사도 평가하고 아래와 같이 상위 3개의 추천 영화를 사용자에게 추천해 줍니다.
[ 홍길동 고객님을 위한 영화추천 3선 ]
1. 어벤저스 ( 예상평점: 5.0 )
2. 반지의제왕 ( 예상평점: 3.6 )
3. 해리포터 ( 예상평점: 3.4 ) |
협업 필터링 알고리즘은 왜 어벤저스를 강력하게 추천했을까요? 그 비밀은 바로 사전 제공된 데이터에 있습니다.
# user_id:
0 : 홍길동
1 : 임꺽정
# item_id:
0 : 해리포터
1 : 반지의제왕
2 : 어벤저스
3 : 엑스맨
4 : 배트맨
# data의 열(column)은 사용자, 영화, 평점 순으로 구성
data = {
'user_id': [0, 0, 1, 1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4],
'item_id': [0, 1, 0, 1, 2, 4, 1, 3, 2, 3, 4, 2, 4, 2],
'rating': [5, 3, 5, 3, 5, 4, 5, 4, 5, 2, 4, 5, 4, 4]
} |
알고리즘에 제공된 데이터 (data)를 보면 홍길동과 임꺽정 고객은 해리 포터와 반지의 제왕에 대한 평점이 동일하기 때문에 영화에 대한 평가가 상당히 유사함을 확인할 수 있습니다.

영화를 조금 더 많이 본 아만다 고객이 어벤저스 평점에 대해 상당히 좋은 점수를 주었기 때문에 이와 유사한 네온 고객에게 어벤저스를 추천할 수 있게 된 것입니다.
아이템 기반 협업 필터링의 구현
아이템 기반 협업 필터링은 아이템 간의 유사도를 평가하고 이를 바탕으로 특정 아이템을 선택 한 사용자에게 유사한 제품을 추천하는 알고리즘입니다.
아래 코드는 사용자가 영화를 선택했을 때 이와 유사한 다른 영화를 추천하는 구현 예시입니다.
import pandas as pd
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# 예시 데이터: 아이템과 카테고리 코드
data = {
'item_id': [0, 1, 2, 3, 4, 5],
'category_code': ["Fantasy", "Marvel", "Marvel", "Marvel", "DC", "Fantasy"]
}
# item id 별 영화 이름
movie_list = [ "해리포터", "어벤저스", "엑스맨", "데드풀" , "배트맨", "반지의제왕" ]
# 사용자 리스트
user_list = [ "홍길동", "임꺽정", "이몽룡", "변사또", "이순신" ]
# 사용자-아이템 상호작용(사용자가 조회 또는 관람) 데이터
# 사용자 0(홍길동) 은 영화 id 0 (해리포터) 시청.
# 사용자 1(임꺽정) 은 영화 id 1, 4(어벤저스, 배트맨) 시청.
# 사용자 2(이몽룡) 은 영화 id 2, 4(엑스맨, 배트맨) 시청.
# 사용자 3(변사또) 은 영화 id 5 (반지의제왕) 시청.
user_data = {
'user_id': [0, 1, 1, 2, 2, 3],
'item_id': [0, 1, 4, 2, 4, 5]
}
# 데이터프레임 생성
items_df = pd.DataFrame(data)
user_df = pd.DataFrame(user_data)
# 아이템-카테고리 매트릭스 생성 (one-hot encoding)
item_category_matrix = pd.get_dummies(items_df.set_index('item_id')['category_code'])
# 아이템 간의 코사인 유사도 계산
item_similarity = cosine_similarity(item_category_matrix)
item_similarity_df = pd.DataFrame(item_similarity, index=item_category_matrix.index, columns=item_category_matrix.index)
def get_item_recommendations( user_id, user_df, item_similarity_df,
n_recommendations=3):
# 사용자가 본 아이템들 추출
user_items = user_df[user_df['user_id'] == user_id]['item_id']
# 아이템 유사도를 기반으로 추천 계산
scores = pd.Series(np.zeros(item_similarity_df.shape[0]), index=item_similarity_df.index)
for item in user_items:
# 각 사용자가 본 아이템의 유사도를 합산
scores += item_similarity_df[item]
# 사용자가 이미 본 아이템 제외
scores = scores.drop(user_items)
# 상위 N 개의 추천 아이템 반환
recommendations = scores.sort_values(ascending=False).head(n_recommendations)
return recommendations
# 추천 수준
def recom_rate( v ):
if v >= 1:
return "강력추천"
else:
return "추천"
for u_idx, user in enumerate(user_list):
print("")
print(f"{user_list[u_idx]} 고객님을 위한 영화추천 3선:")
recommendations = get_item_recommendations(u_idx, user_df, item_similarity_df)
# 추천 영화와 추천 수준을 출력
num = 1
for i, val in recommendations.items():
print( f"{num}.", movie_list[i] + " / ", recom_rate(int(val)))
num += 1 |
코드를 실행하면 get_item_recommendations 함수는 협업 필터링 알고리즘을 통해 아이템(영화) 간의 유사도 평가하고 아래와 같이 상위 3개의 추천 영화를 사용자에게 추천해 줍니다.
[ 이몽룡 고객님을 위한 영화추천 3선 ]
1. 어벤저스 / 강력추천
2. 데드풀 / 강력추천
3. 해리포터 / 추천 |
아이템 기반 협업 필터링 알고리즘은 기존 고객이 선택하거나 이미 본 영화를 기반으로 유사한 영화를 추천하는데요, 위와 같은 영화를 추천한 이유는 해당 고객의 기록을 보면 이해할 수 있습니다.
사용자 시청 정보
# 사용자-아이템 상호작용(사용자가 조회 또는 관람) 데이터
# 사용자 0(홍길동) 은 영화 id 0 (해리포터) 시청.
# 사용자 1(임꺽정) 은 영화 id 1, 4(어벤저스, 배트맨) 시청.
# 사용자 2(이몽룡) 은 영화 id 2, 4(엑스맨, 배트맨) 시청.
# 사용자 3(변사또) 은 영화 id 5 (반지의제왕) 시청.
user_data = {
'user_id': [0, 1, 1, 2, 2, 3],
'item_id': [0, 1, 4, 2, 4, 5]
} |
영화 분류 정보
data = {
'item_id': [0, 1, 2, 3, 4, 5],
'category_code': ["Fantasy", "Marvel", "Marvel", "Marvel", "DC", "Fantasy"]
} |
코드에 구현된 시청 데이터에서 이몽룡은 ‘엑스맨’ 과 ‘배트맨’을 시청한 것을 확인할 수 있습니다.
영화 분류 데이터에 따르면 엑스맨은 ‘Marvel’, 배트맨은 ‘DC’로 분류가 되어 있는데요, 아이템 기반 협업 필터링 알고리즘은 이몽룡 고객이 Marvel에 속하는 영화 ‘엑스맨’에 대해 시청 이력이 있기 때문에 Marvel로 분류되어 있는 다른 영화들 ‘어벤저스’, ‘데드풀’을 강력 추천하게 된 것입니다.
반면에 영화 배트맨이 속한 ‘DC’ 항목의 영화 중에서는 추천할 영화가 없기 때문에 하나의 영화를 더 추천하는 과정에서 데이터 순서 상 가장 앞에 있는 ‘해리포터’를 임의로 추천하였습니다.

지금까지 사용자 기반 추천과 아이템 기반 추천 방식의 구현 방법을 알아보았습니다. 일반적으로 알고리즘 추천 시스템을 구현할 때 아이템 기반 추천 알고리즘이 사용자 기반의 추천 알고리즘보다 성능이 좋아 알고리즘 추천 시스템에 많이 활용되고 있습니다.
이는 사람의 마음은 환경에 따라 자주 변하기 마련이지만 제품 또는 서비스의 유사도는 상대적으로 변동이 적기 때문입니다.
하지만 아이템 기반 알고리즘 추천 시스템이 모든 환경에서 더 잘 동작한다고 평가하기는 어렵기 때문에 알려드린 두 가지 알고리즘 추천 시스템 사례를 비교해 보고 필요한 추천 시스템에 더 적합한 알고리즘을 도입하여 활용하는 것이 중요합니다.
알고리즘 추천 시스템 ‘협업 필터링’을 통해
사용자 맞춤 정보를 제공해 보세요!

협업 필터링은 사용자 데이터를 바탕으로 해당 사용자가 필요로 하는 정보나 제품들을 손쉽게 추천받을 수 있도록 도와줍니다.
과거부터 현재까지 많은 기업들이 협업 필터링과 같은 개인화 알고리즘을 통해 사용자에게 편의 기능을 제공하고 있으며 이를 바탕으로 한 충성 고객을 확보하고 있습니다.
서비스 내에서 콘텐츠를 추천하거나 제품에 대한 마케팅이 필요하다면 이랜서에서 알려드리는 협업 필터링 알고리즘 가이드를 참고해 사용자 알고리즘 추천 시스템을 활용해 보세요. 편의성에 기반 한 사용자 만족도를 높임과 동시에 폭발적인 고객 유입을 이끌어 낼 수 있을 것입니다.
고객을 사로잡는 고객 경험 상승 콘텐츠 시리즈
▶️ [만보기 어플 만들기] Kotlin으로 만보기 앱 개발하는 방법
▶️ 슈퍼 앱, 궁극의 올인원 서비스로 고객을 확보하세요!
▶️ AI 챗봇, Chat GPT API를 활용하여 서비스 특화 AI 챗봇을 만드는 방법
간편하고 깔끔한 코드 활용을 도와주는 개발자 업그레이드 콘텐츠
▶️ 정규 표현식; 자바 정규식을 활용해서 문자열을 손쉽게 처리하는 방법
▶️ Maven vs Gradle, 20년차 개발자는 실무에서 이렇게 활용합니다.
▶️ React Query를 통한 데이터 패칭, 캐싱, 동기화 방법 총정리
“알고리즘을 활용한 고객 맞춤형 서비스 도입
아직도 고민 중이신가요?”
충성 고객을 확보하기 위해서는 데이터 분석에 기반한 알고리즘 활용이 필수입니다. 알고리즘을 적용하고 비즈니스 경쟁력을 높여보세요. 대한민국 No.1 IT 인재 매칭 플랫폼 이랜서에서 프로젝트 최적합 알고리즘 전문가를 매칭해 드립니다.

이랜서는 24년동안 축적한 노하우와 데이터를 바탕으로 프로젝트에 가장 적합한 IT 전문가를 매칭하는 IT 인재 매칭 플랫폼입니다.
“경력 기술서와 이력서만으로
실력있는 IT 전문가를 채용할 수 있을까요?”
Java부터 Python, React, Vue, jQuery, JavaScript, TypeScript, Next js, NestJS, Flutter, Kotlin, Svelte, C 언어, C++, Swift, React Native, .Net까지 프로그래밍 언어만 해도 수십 개가 넘습니다. 경력 기술서와 이력서만으로 IT 전문가의 능력을 확인할 수 있을까요?
“실력과 인성 모두 검증된 IT 전문가를 매칭해 주는
이랜서에 어떤 프로젝트든 믿고 맡깁니다.”

이랜서는 24년의 노하우와 데이터를 활용하여 객관적으로 전문성과 인성(협업 능력) 모두 철저하게 검증하여 프로젝트에 가장 적합한 IT 전문가를 매칭합니다.
프로젝트 최적합 IT 전문가를 매칭하기 위해
24년 동안 노하우와 데이터를 쌓았습니다.
이랜서는 프로젝트에 가장 적합한 IT 전문가를 매칭하기 위해 24년 동안 약 1.5억 개의 서비데이스 데이터와 350만 개의 프리랜서 평가 데이터를 쌓고 약 6만 건 이상의 프로젝트에 최적합 IT 전문가를 매칭했습니다.
IT 전문가의 전문성부터 인성(협업 능력)까지 철저하게 검증하여 프로젝트에 가장 적합한 IT 전문가를 매칭한 결과 이랜서를 사용한 기업들의 프로젝트 재의뢰율 98%를 달성하고 있습니다.

전사적 자원 관리 프로그램 개발을 위한
ERP, SAP 전문가부터
SI 업체, 아웃소싱, 유지 보수, RPA
프로젝트를 위한 전문가까지
정규 표현식과 정규식 문법, 리스트 및 연산자를 활용한 가독성 높은 코딩능력, Maven, Gradle 등의 빌드 도구와 Styled Components, tailwind 등을 활용한 안정적인 프로그램 개발, 반응형 웹과 고객 여정 지도, 디자인 시스템, 디자인 가이드 등을 활용한 고객 친화적 서비스 기획, 피그마(Figma)와 Adobe XD, 포토샵, 일러스트, Unity 3D, Blender 3D, 스케치 업 등 다양한 디자인 툴을 활용한 맞춤형 UI/UX 디자인까지
“이랜서 하나로 모두 가능합니다.”

프로젝트 맞춤형 최적합 IT 전문가를 찾으시나요?
대한민국 No.1 IT 인재 매칭 플랫폼 이랜서에
-> 회원 가입만 하세요.
-> 24시간 안에 전담 매니저가 연락을 드립니다.
-> 끝입니다. 이게 다냐구요? 네, 이게 다입니다.
-> 급하시다고요? 전화 주세요. 02-545-0042
24년의 노하우와 데이터를 바탕으로 검증된 IT 프리랜서를 매칭해 드립니다.



